Text2Human: Text-Driven Controllable Human Image Generation
- 1S-Lab, Nanyang Technological University
- 2SenseTime Research

The lady wears a short-sleeve T-shirt with the pure color pattern and a short and denim skirt.

The man wears a short-sleeve T-shirt with the pure color pattern and short pants with the pure color pattern.

A lady wearing a sleeveless pure-color shirt and long jeans.

The man wears a sleeveless shirt with the pure color pattern and short pants with the pure color pattern.

The man wears a long and floral shirt and long pants with the pure color pattern.

A lady wears a short-sleeve pure-color T-shirt and long pure-color pants. She also wears a hat.

A man wears a short-sleeve and short rompers with denim meterials.

A lady wears a short-sleeve and a short floral dress.

A man wears a shirt and long pure-color pants with an unzipped denim outer clothing.

The man wears a sleeveless shirt with the pure color pattern and short pants with the pure color pattern.

A lady wears a sleeveless and long rompers with denim meterials.

The guy wears a short-sleeve shirt with the pure color pattern and long denim pants.
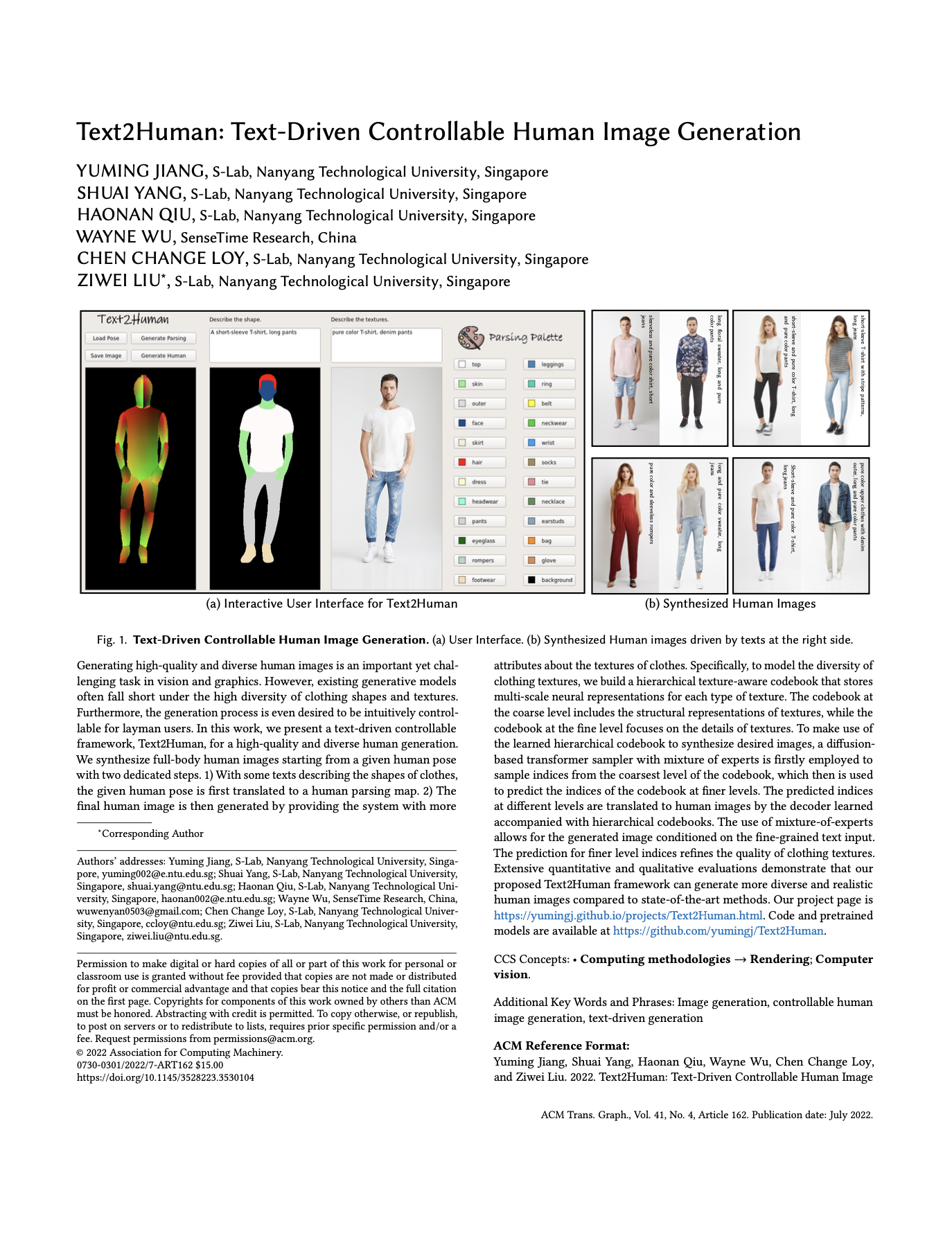

You can select the attributes to customize the synthesized human images.
































DeepFashion-MultiModal is a large-scale high-quality human dataset with rich multi-modal annotations. It has the following properties:
1. It contains 44,096 high-resolution human images, including 12,701 full body human images.
2. For each full body images, we manually annotate the human parsing labels of 24 classes.
3. For each full body images, we manually annotate the keypoints.
4. We extract DensePose for each human image.
5. Each image is manually annotated with attributes for both clothes shapes and textures.
6. We provide a textual description for each image.

@article{jiang2022text2human,
title={Text2Human: Text-Driven Controllable Human Image Generation},
author={Jiang, Yuming and Yang, Shuai and Qiu, Haonan and Wu, Wayne and Loy, Chen Change and Liu, Ziwei},
journal={ACM Transactions on Graphics (TOG)},
volume={41},
number={4},
articleno={162},
pages={1--11},
year={2022},
publisher={ACM New York, NY, USA},
doi={10.1145/3528223.3530104}
}
EVA3D proposes a compositional framework to generate 3D human from 2D image collections.
StyleGAN-Human investigates the "data engineering" in unconditional human generation.
Talk-to-Edit proposes a StyleGAN-based method and a multi-modal dataset for dialog-based facial editing.
CelebA-Dialog is a large-scale visual-language face dataset with rich fine-grained labels and textual descriptions.
DualStyleGAN proposes StyleGAN-based Cartoonization.
AvatarCLIP proposes a zero-shot text-driven framework for 3D avatar generation and animation
For more interesting researches, please visit the MMLab@NTU website.We referred to the project page of Nerfies and AvatarCLIP when creating this project page.